社区内有人发起了一个讨论,关于JVM是否一定需要GC?他们认为应用程序的回收目标是构建一个仅用来处理内存分配,而不执行任何真正的内存回收操作的 GC。即仅当可用的 Java 堆耗尽的时候,才进行顺序的 JVM 停顿操作。
首先需要理解为什么需要GC。随着应用程序所应对的业务越来越庞大、复杂,用户越来越多,没有GC就不能保证应用程序正常进行。而经常造成STW的GC又跟不上实际的需求,所以才会不断地尝试对GC进行优化。
社区的需求是尽量减少对应用程序的正常执行干扰,这也是业界目标。Oracle在JDK7时发布G1 GC的目的是为了减少应用程序停顿发生的可能性,让我们通过本文来了解G1 GC所做的工作。
JVM发展历史简介
还记得机器猫吗?他和康夫有一张书桌,书桌的抽屉其实是一个时空穿梭通道,让我们操作机器猫的时空机器,回到1998年。那年的12月8日,第二代Java平台的企业版J2EE正式对外发布。为了配合企业级应用落地,1999年4月27日,Java程序的舞台—Java HotSpot Virtual Machine(以下简称HotSpot )正式对外发布,并从这之后发布的JDK1.3版本开始,HotSpot成为Sun JDK的默认虚拟机。

GC发展历史简介
1999年随JDK1.3.1一起来的是串行方式的Serial GC ,它是第一款GC,并且这只是起点。此后,JDK1.4和J2SE1.3相继发布。2002年2月26日,J2SE1.4发布,Parallel GC 和Concurrent Mark Sweep (CMS)GC跟随JDK1.4.2一起发布,并且Parallel GC在JDK6之后成为HotSpot默认GC。
HotSpot有这么多的垃圾回收器,那么如果有人问,Serial GC、Parallel GC、Concurrent Mark Sweep GC这三个GC有什么不同呢?请记住以下口令:
如果你想要最小化地使用内存和并行开销,请选Serial GC;
如果你想要最大化应用程序的吞吐量,请选Parallel GC;
如果你想要最小化GC的中断或停顿时间,请选CMS GC。
那么问题来了,既然我们已经有了上面三个强大的GC,为什么还要发布Garbage First(G1)GC?原因就在于应用程序所应对的业务越来越庞大、复杂,用户越来越多,没有GC就不能保证应用程序正常进行,而经常造成STW的GC又跟不上实际的需求,所以才会不断地尝试对GC进行优化。
为什么名字叫做Garbage First(G1)呢?
因为G1是一个并行回收器,它把堆内存分割为很多不相关的区间(Region),每个区间可以属于老年代或者年轻代,并且每个年龄代区间可以是物理上不连续的。
老年代区间这个设计理念本身是为了服务于并行后台线程,这些线程的主要工作是寻找未被引用的对象。而这样就会产生一种现象,即某些区间的垃圾(未被引用对象)多于其他的区间。
垃圾回收时实则都是需要停下应用程序的,不然就没有办法防治应用程序的干扰 ,然后G1 GC可以集中精力在垃圾最多的区间上,并且只会费一点点时间就可以清空这些区间里的垃圾,腾出完全空闲的区间。
绕来绕去终于明白了,由于这种方式的侧重点在于处理垃圾最多的区间,所以我们给G1一个名字:垃圾优先(Garbage First)。
G1 GC基本思想
G1 GC是一个压缩收集器,它基于回收最大量的垃圾原理进行设计。G1 GC利用递增、并行、独占暂停这些属性,通过拷贝方式完成压缩目标。此外,它也借助并行、多阶段并行标记这些方式来帮助减少标记、重标记、清除暂停的停顿时间,让停顿时间最小化是它的设计目标之一。
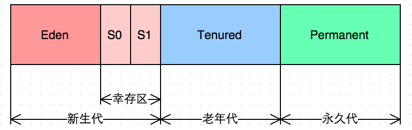
G1回收器是在JDK1.7中正式投入使用的全新的垃圾回收器,从长期目标来看,它是为了取代CMS 回收器。G1回收器拥有独特的垃圾回收策略,这和之前提到的回收器截然不同。从分代上看,G1依然属于分代型垃圾回收器,它会区分年轻代和老年代,年轻代依然有Eden区和Survivor区,但从堆的结构上看,它并不要求整个Eden区、年轻代或者老年代在物理上都是连续。
综合来说,G1使用了全新的分区算法,其特点如下所示:
并行性:G1在回收期间,可以有多个GC线程同时工作,有效利用多核计算能力;
并发性:G1拥有与应用程序交替执行的能力,部分工作可以和应用程序同时执行,因此,一般来说,不会在整个回收阶段发生完全阻塞应用程序的情况;
分代GC:G1依然是一个分代收集器,但是和之前的各类回收器不同,它同时兼顾年轻代和老年代。对比其他回收器,或者工作在年轻代,或者工作在老年代;
空间整理:G1在回收过程中,会进行适当的对象移动,不像CMS只是简单地标记清理对象。在若干次GC后,CMS必须进行一次碎片整理。而G1不同,它每次回收都会有效地复制对象,减少空间碎片,进而提升内部循环速度。
可预见性:由于分区的原因,G1可以只选取部分区域进行内存回收,这样缩小了回收的范围,因此对于全局停顿情况的发生也能得到较好的控制。
随着G1 GC的出现,GC从传统的连续堆内存布局设计,逐渐走向不连续内存块,这是通过引入Region概念实现,也就是说,由一堆不连续的Region组成了堆内存。其实也不能说是不连续的,只是它从传统的物理连续逐渐改变为逻辑上的连续,这是通过Region的动态分配方式实现的,我们可以把一个Region分配给Eden、Survivor、老年代、大对象区间、空闲区间等的任意一个,而不是固定它的作用,因为越是固定,越是呆板。
G1 GC垃圾回收机制
通过市场的力量,不断淘汰旧的行业,把有限的资源让给那些竞争力更强、利润率更高的企业。类似地,硅谷也在不断淘汰过时的人员,从全世界吸收新鲜血液。经过半个多世纪的发展,在硅谷地区便形成只有卓越才能生存的文化。本着这样的理念,GC承担了淘汰垃圾、保存优良资产的任务。
G1 GC在回收暂停阶段会回收最大量的堆内区间(Region),这是它的设计目标,通过回收区间达到回收垃圾的目的。这里只有一个例外情况,这个例外发生在并行标记阶段的清除(Cleanup)步骤,如果G1 GC在清除步骤发现所有的区间都是由可回收垃圾组成的,那么它会立即回收这些区间,并且将这些区间插入到一个基于LinkedList实现的空闲区间队列里,以待后用。因此,释放这些区间并不需要等待下一个垃圾回收中断,它是实时执行的,即清除阶段起到了最后一道把控作用。这是G1 GC和之前的几代GC的一大差别。
G1 GC的垃圾回收循环由三个主要类型组成:
年轻代循环
多步骤并行标记循环
混合收集循环
Full GC
在年轻代回收期,G1 GC暂停应用程序线程,然后从年轻代区间移动存活对象到Survivor区间或者老年区间,也有可能是两个区间都会涉及。对于一个混合回收期,G1 GC从老年区间移动存活对象到空闲区间,这些空闲区间也就成为了老年代的一部分。
G1的区间设计灵感
为了加快GC的回收速度,HotSpot的历代GC都有自己的不同的设计方案,区间概念在软件设计、架构领域并不是一个新名词,关系型数据库、列式数据库最先使用这个概念提升数据存、取速度,软件架构设计时也广泛使用这样的分区概念加快数据交换、计算。
为什么会有区间这个设计想法?大家一定看过电视剧《大宅门》吧?大宅门所描述的北京知名医术世家白家是这本电视剧的主角。白家有三兄弟,没有分家之前,由老爷子一手掌管全家,老爷子看似是个精明人,实质是个糊涂的人,否则也不会弄得后来白家家破人散。白家的三兄弟在没有分家之前,老大一家很老实,老二很懦弱,性格像女人,虽然肚子里明白道理,但是不敢出来做主。老三年轻时混蛋一个,每次出外采购药材都要私吞家里的银两,造成账目混乱。老大为了家庭和睦,一直在私下倒贴银两,让老爷子能够看到一本正常的账目。这样的一家子聚在一起,迟早家庭内部会出现问题,倒不如分家,你也不用算计家里的钱了,分给你,分给你的钱有本事守住,没本事就一直拮据下去吧。这就是最原始的分区(Region)概念。
我们回到技术,看看HBase的RegionServer设计方式。在HBase内部,所有的用户数据以及元数据的请求,在经过Region的定位,最终会落在RegionServer上,并由RegionServer实现数据的读写操作。RegionServer是HBase集群运行在每个工作节点上的服务。它是整个HBase系统的关键所在,一方面它维护了Region的状态,提供了对于Region的管理和服务;另一方面,它与Master交互,上传Region的负载信息上传,参与Master的分布式协调管理。

HRegionServer与HMaster以及Client之间采用RPC协议进行通信。HRegionServer向HMaster定期汇报节点的负载状况,包括RS内存使用状态、在线状态的Region等信息。在该过程中HRegionServer扮演了RPC客户端的角色,而HMaster扮演了RPC服务器端的角色。HRegionServer内置的RpcServer实现了数据更新、读取、删除的操作,以及Region涉及到Flush、Compaction、Open、Close、Load文件等功能性操作。
Region是HBase数据存储和管理的基本单位。HBase使用RowKey将表水平切割成多个HRegion,从HMaster的角度,每个HRegion都纪录了它的StartKey和EndKey(第一个HRegion的StartKey为空,最后一个HRegion的EndKey为空),由于RowKey是排序的,因而Client可以通过HMaster快速的定位每个RowKey在哪个HRegion中。HRegion由HMaster分配到相应的HRegionServer中,然后由HRegionServer负责HRegion的启动和管理,和Client的通信,负责数据的读(使用HDFS)。每个HRegionServer可以同时管理1000个左右的HRegion。
再来看看软件系统架构方面的分区设计。以任务调度为例,假设我们有一个中心调度服务,那么当数据量不断增多,这个中心调度服务一定会遇到性能瓶颈,因为所有的请求都会最终指向它。为了解决这个性能瓶颈,我们可以将任务调度拆分为多个服务,即这多个服务都可以处理任务调度工作,那么问题来了,每个任务调度服务处理的源数据是否需要完全一致?
根据华为公司发布的专利发明,显示他们对于每一个任务调度服务有数据来源区分的操作,即按照任务调度数量对源数据进行划分,比如3个任务调度服务,那么源数据按照行号对3取余的方式划分,如果运行了一段时间之后,任务调度服务出现了数量上的增减,那么这个取余划分需要重新进行,要按照那个时候的任务调度数量重新划分区间。
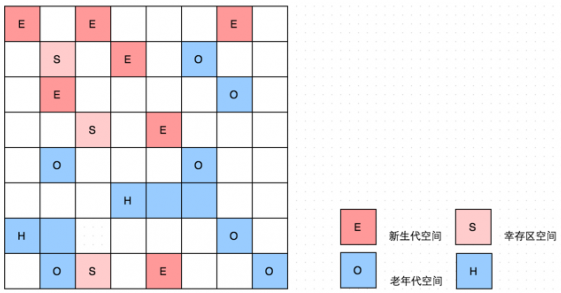
回到G1。在G1中,堆被平均分成若干个大小相等的区域(Region)。每个Region都有一个关联的Remembered Set(简称RS),RS的数据结构是Hash表,里面的数据是Card Table (堆中每512byte映射在card table 1byte)。
简单的说RS里面存在的是Region中存活对象的指针。当Region中数据发生变化时,首先反映到Card Table中的一个或多个Card上,RS通过扫描内部的Card Table得知Region中内存使用情况和存活对象。在使用Region过程中,如果Region被填满了,分配内存的线程会重新选择一个新的Region,空闲Region被组织到一个基于链表的数据结构(LinkedList)里面,这样可以快速找到新的Region。
总结
没有GC机制的JVM是不能想象的,我们只能通过不断优化它的使用、不断调整自己的应用程序,避免出现大量垃圾,而不是一味认为GC造成了应用程序问题。
G1GC优化参考文档
作者介绍
周明耀,2004年毕业于浙江大学,工学硕士,国外投资银行12年工作经验,4年分布式系统、物联网工作经验,10年技术团队管理经验。IBM开发者论坛专家作者、InfoQ专栏作者,著有《大话Java性能优化》、《深入理解JVM&G1 GC》,提交分布式计算领域发明专利超过15项。





 联系电话:0512-55008018
联系电话:0512-55008018 传真:0512-55008018
传真:0512-55008018 邮箱:sales@baoding-soft.com
邮箱:sales@baoding-soft.com 地址:昆山市巴城镇学院路828号浦东软件园区1栋4楼A座
地址:昆山市巴城镇学院路828号浦东软件园区1栋4楼A座 微信交流
微信交流 关注我们
关注我们 首页
首页

